Autor: Alfonso Tarancón Lafita.
Categoría: Articulo – Área: Redes Sociales.
Un poco de Historia sobre algunos avances precursores en Sociología y en Física.
La sociología y la física son dos bien asentadas disciplinas, entre la que en los últimos tiempos Internet y la Informática se empeñan en tender puentes si bien los arquitectos a ambos lados del rio no siempre se muestran convencidos de la necesidad de cruzarlos.
Se han ido produciendo acercamientos, confluencias, investigaciones multidisciplinares a todo lo largo del siglo XX, pero sólo con la llegada del uso masivo de los Ordenadores e Internet, estos tímidos escarceos han dejado paso a una avalancha de colaboraciones y sobre todo a una imperiosa necesidad de convergencia, a una actualización de las herramientas, lo procedimientos e incluso de algunas cuestiones básicas.
Para comprender mejor el proceso de convergencia, citaremos alguna de las investigaciones fundamentales que han mostrado el camino actual de colaboración.
El primer experimento es el realizado por el psicólogo social Milgram en 1967 en Estados Unidos. Milgram seleccionó un conjunto de personas en USA al azar en la guía telefónica de las ciudades de Omaha y Nebraska. Estas personas eran completamente desconocidas para él. El experimento consistía en hacerles llegar una carta sin tener ni idea de donde vivían. Para ello Milgran envió cartas a personas que el conocía y que imaginaba que podrían conocer a otras personas que finalmente conocieran al destinatario. La única información que se les daba era el nombre de la persona a la que debía llegar la carta finalmente. Y la pregunta básica a responder en el experimento era ¿Cuántos pasos darán las cartas (en media) antes de llegar a su destino?
La mayoría del staff y los profesionales del campo, suponían que casi todas las cartas se perderían y que si alguna llegaba seria tras decenas o cientos de saltos.
Pero no fue así: sorprendentemente el objetivo se alcanzó para un buen número de destinatarios, y lo que es más importante, el número medio de pasos para llegar al destino fue mucho más pequeño del esperado. De las 296 cartas, 232 se perdieron, pero 64 llegaron a su destino. ¡Y el número medio de pasos fue de 6!
Algo había en la estructura de las relaciones que hacia que las suposiciones básicas de la psicología social no funcionaran del todo. Algo había que lograba que a pesar de los millones de personas involucradas, de lo improbable de que dos personas al azar se conozcan, al final, la conexión se producía entre cualesquiera dos personas, y de forma sorprendentemente rápida.
Hoy se conoce la estructura matemática subyacente, y conocemos esta propiedad de cercanía en una sociedad con miles de millones de personas, como la propiedad de “Mundo pequeño” (o con cierta trivialización, a veces se habla de “Aldea Global”).
El segundo experimento corresponde con la generación de Redes y su análisis. Entre 1970 y 1972 W. W. Zachary realizó un estudio de las relaciones entre los 34 miembros de un Club de Karate Universitario en USA, basado principalmente en la amistad mantenida fuera del Club. Esto permitió a Zachary elaborar un sociograma donde las personas estaban representadas por círculos y la relaciones por lineas uniendo a las personas relacionadas. El gráfico, todo un clásico, puede verse en la figura.
Los miembros de este club finalmente tuvieron una fuerte disensión y el Club se rompió en dos mientras Zachary estaba realizando el estudio.
El hecho importante es que Zachary fue capaz en base a las relaciones establecidas en la figura, de predecir correctamente qué nuevo Club elegiría cada uno (salvo para una única persona, el número 10, que como se ve está en la frontera de las comunidades con sólo dos relaciones).
Curiosamente este trabajo paso casi desapercibido durante 30 años, y sólo a partir de 2002, con la madurez de la disciplina de Redes Complejas, ha recibido un reconocimiento global.
Mientras esto ocurría en el lado de la sociología, en el campo de la Física, algunos investigadores se dedicaban a temas aparentemente un tanto peregrinos, como por ejemplo el estudio de “Avalanchas en Pilas de Arena”. Curiosamente a mi de pequeño me llamó la atención que mi abuelo era capaz de calcular el peso de un montón de trigo sólo sabiendo su altura. Recuerdo como en el cálido verano se dejaba caer el trigo en el suelo, y se formaba un montón cónico, que crecía un poco, de repente se rompía por la punta y se derramaba alrededor haciéndose un poco más ancho, de nuevo a crecer, etc.
Pues bien este fenómeno fue estudiado matemáticamente, como un ejemplo de los fenómenos de “avalancha”, que consisten en procesos que se desarrollan de forma suave, local, aparentemente sin cambios (voy echando granos y el montón va creciendo suavemente) hasta que se produce una disrupción, un cambio brusco que implica a una gran parte del sistema, un fenómeno “global” (el derrumbe del pico del montón y su dispersión por el montón).
La investigación en Física condujo a la aplicación de las mismas herramientas a fenómenos más “cotidianos” o interesantes, como por ejemplo la ruptura de materiales, la formación de fallas o la previsión de terremotos, todos ellos con un fondo matemático muy similar al usado para el estudio de las pilas de arena.
Incluso algunos físicos se atrevieron a estudiar procesos similares que se desarrollaban en la Sociedad: ¿Cómo se propaga una enfermedad en una sociedad de millones de personas? ¿Cómo se comporta una muchedumbre para salir de un edificio tras un incendio? ¿Como logran los estorninos hacer esas evoluciones coherentes que parecen mágicas en el cielo?
Aclarar aquí que el punto de vista de los físicos era siempre estadístico: no interesaba estudiar el comportamiento de una persona concreta, sino de las propiedades del conjunto. Por ejemplo es imposible predecir por qué puerta concreta saldrá una persona afectada por el incendio, pero sí es predecible cuantas saldrán por cada una.
Todo esto se situaba en el terreno de la ciencia básica y el objetivo era buscar modelos que con las mínimas premisas reprodujeran el comportamiento real lo mejor posible.
El advenimiento de los Ordenadores, la Informática, Internet y las Redes sociales
En los 70 y 80 llegan los Ordenadores y poco después las Redes de interconexión entre ellos. La conectividad de los ordenadores era una Red muy interesante desde el punto de vista matemático y con aplicaciones prácticas, para dar respuestas a preguntas como por ejemplo: “Como deben conectarse entre si miles de ordenadores para que la red resista fallos de algunos de ellos” (Fallos tanto eléctricos, como humanos, por ataques de hackers o incluso por conflictos militares…)
No obstante el estudio de “Redes Complejas” no dejaba de ser una disciplina circunscrita en la “Física Teórica”, con representantes en unas pocas Universidades y Centros de Investigación. Una Rara Avis.
Y en esto llego Internet a todos los hogares del mundo desarrollado. Se acabo la diversión: no más trabajar tranquilamente en un despacho de una Torre de Marfil. El desarrollo de las Redes Sociales se muestra imparable. Geocities en 1994, Sixdegrees en 1995 y tras la explosión de la burbuja en 2000 de la que nos rescató la irrupción de Google, aparecen Myspace, Linkedin y Facebook en 2003. Twitter llega en 2006. Otras decenas, cientos de iniciativas nacen, crecen, a veces se reproducen, y mueren. El ecosistema de sitios web, redes sociales se hace tan complejo que es imposible abarcarlo. Jóvenes informáticos, emprendedores, empresarios, especuladores, inversores, todo tipo de fauna se lanza al ruedo de la creación de redes sociales, desde el carácter más general al más específico. Hoy no hay tema en el mundo que no tenga una red social para relacionarse.
Y las grandes redes globales: Facebook, twitter, Instagram, incluso YouTube, etc… forman un sistema de comunicación global instantáneo inimaginable hace unos años. Ningún escritor de ciencia ficción había previsto esto ni de lejos. (De hecho ningún escritor de ciencia ficción había sido capaz de predecir el móvil: hoy puede verse con vergüenza ajena como sociedades en el año 5000 capaces de navegar entre galaxias en un parpadeo, para hablar tenían que ir a una cabina telefónica, eso si, con muchas luces parpadeantes de colores).
Hoy en día las Redes Sociales están presentes en casi todos los aspectos de la vida cotidiana. En los que no está, todo el mundo da por hecho que pronto estarán.
Hoy todos los jóvenes participan activamente no en una sino en varias redes sociales. Y quien empieza no las abandona, por lo que el perfil de edad va creciendo con el tiempo. En unos años todo el mundo participará en ellas o en sus herederas, ya sabemos que todo en Internet es efímero.
Mucho se ha hablado del origen, de las razones del éxito arrollador de las redes sociales. La condición sine equanon es por supuesto el desarrollo tecnológico y la capacidad adquisitiva de la sociedad. Socialmente hablando, desde mi punto de vista hay dos pilares para el triunfo: por un lado una componente voyeurista de la gente, por lo que les gusta ver a los demás, seguir su vida, los detalles cotidianos e incluso si puede ser, íntimos. Y por otro la componente narcisista, la atracción irrefrenable para mostrarse en público y que los demás te vean casi al desnudo.
He sentido pudor muchas veces de ver confesiones en la Red de personas que no se atreven a decirlo en privado a sus allegados más íntimos; pero más allá de casos tal vez patológicos, en general la gente cuenta su vida casi en directo a todo aquel que le quiera escuchar. Adoran ser “seguidos”, ser “visualizados”, ser “leídos”.
No me deja de sorprender que ahora, tras una reunión donde se decide el destino de la Unión Europea, o de las armas nucleares, o de la guerra en un lejano rincón de África, el resultado de esa decisión que puede suponer hasta la vida o muerte de miles de personas, se anuncie con un tweet. Nadie quiere perder el protagonismo de ser el primero en decirlo, y que quede claro que quien lo dice es el más poderoso, el mandamás en el asunto, el macho alfa del Clan.
El Ecosistema de Negocios basado en las Redes Sociales en Internet
Una vez embarcados cientos de millones de personas en esa vorágine, en el ecosistema de Internet aparecen oportunidades de negocio sin límite, y por tanto especies para rellenar esos nichos ecológicos. Las Redes sociales y la posibilidad de rastreo las convierte en un mercado global donde conocer en tiempo real lo que esta pasando, de que se habla, si se habla bien o mal es posible y además convertible en dinero.
Cuando tenemos cientos de millones de personas en una Red, eso es “casi” el mundo real. Lo que pasa en la Red se confunde con la realidad fuera de ella. Según el número de personas se amplia con el tiempo en cantidad y perfiles sociales, de edad… mas fidedigna es la Red.
En la Red la gente habla sin tapujos, se siente libre, necesita expresar sus deseos, sus apetencias, sus necesidades, sus opiniones, sus demandas. Todo lo que se opina se dice; sobre cualquier tema que se nos ocurra habrá miles de personas que han hablado, discutido, debatido. En el mundo se envián 500 millones de tweets al día, da para mucho.
Y lo que es más importante: la propia actividad en la Red de sus usuarios influye de forma importante sobre el resto: la opiniones de unos a favor o en contra se propagan rápidamente ganando adeptos, seguidores, defensores activos que a su vez generan más opinión: es lo que llamamos una reacción en cadena, que es algo muy efectivo para que las cosas se propaguen en sistemas de millones de personas de forma rapidísima.
Es pieza clave la sensación en la personas de que participan de forma activa, la sensación de que lo que hacen en una red es visto por otros. Es una respuesta a los medios tradicionales, a los políticos tradicionales, que ciertamente son unidireccionales: hablan pero no escuchan; en la comunicación a la antigua uno habla y millones escuchan sin poder hablar entre si. En la comunicación moderna, gracias a Internet se ha roto esa dinámica y millones pueden hablar entre si sin depender de los poderosos. Es una sensación de libertad, de independencia, de ruptura de normas que ha llevado a millones de personas a la vuelta a la actividad política o al inicio de la misma en los más jóvenes.
El inesperado encuentro de Sociología, Física, Cloud, Supercomputación y Big Data
Tenemos pues un mundo virtual, el mundo donde se desarrolla toda esta frenética actividad, y que gracias a los grandes avances en Supercomputación, en almacenamiento, en rastreo, con nombres pomposos como Big Data, podemos ver sentados desde nuestro sillón, analizar como con un microscopio, ver todos los detalles en cualquier momento, analizar personas individuales, grupos, ciudades, países, modas, opiniones, compras, ventas, propuestas, ideas de negocio, noticias… en fin, todo lo imaginable. Todo en tiempo real. También rebobinar, e incluso a veces, predecir…
De modo que la actividad clásica de la sociología, del análisis de mercados, de la publicidad y el marketing, que es saber lo que pasa en la sociedad por un lado, y por otro influir sobre la sociedad, ahora puede desarrollarse en gran parte dentro de las Redes, sin salir a la calle, digamos. Hay decenas de herramientas informáticas para hacer este análisis, desde muy diferentes puntos de vista.
En esta fase inicial del uso de la Redes como origen de datos para análisis hay numerosos problemas aun sin resolver.
En resumen, si la ventaja es la cantidad, el inconveniente es la calidad.
En una encuesta presencial puedo hacer una pregunta clara y directa, e incluso puedo insistir y reconducir la respuesta hasta llegar a conocer con precisión la opinión del encuestado sobre lo que yo quiera. En una Red social, las opiniones están dadas, debo extraer información de lo ya dicho.
A cambio tengo millones de opiniones.
Tal vez sea necesario un cambio en la mentalidad a la hora de encarar el análisis en Redes: no me sirve tanto (aunque también) para dar respuestas a MIS preguntas, como para saber QUÉ está pasando en el Mundo. Digamos que en vez de preguntar “Qué opina la gente de esto”, la pregunta es más “De qué opina la gente y cómo”.
Disponer de muchos datos a veces hace posible ambos tipos de preguntas, pero desde luego el análisis de ingentes cantidades de información hace necesario el uso de nuevas herramientas.
Volvamos a los Físicos, que estaban en sus Torres de Marfil, con sus viejas pizarras, sus artículos en sesudas revistas científicas; de repente ven que todo lo que habían estudiado con afán académico, ahora estaba en boca de todos. Grandes empresas se encontraban con un aluvión de información que eran incapaces de ver, de leer siquiera, y mucho menos de analizar para extraer información relevante. Y resulta que los Físicos sabían como enfrentarse al problema. Al fin y al cabo para ellos las avalanchas de granos de arena y (por ejemplo) la creación de un “viral” en Internet son fenómenos que responden a un modelo subyacente idéntico… que son lo mismo, vamos. Y en esos fenómenos llevaban trabajando muchos años: estaban preparados para dar el salto al estudio de las Redes Sociales, donde además obtendrían fácilmente fondos para seguir sus investigaciones.
De esta manera la “Física de Sistemas Complejos” pasó de un reducto de iniciados a ser demandada (y pagada) por periodistas, sociólogos, expertos en marketing, en ventas, políticos en campaña, gobiernos, agencias de inteligencia, cadenas de TV, artistas …
Cómo se Rastrean datos y se generan redes complejas desde los datos de Internet
En la base de todo están los Datos. Y hoy se generan en cantidades gigantescas. Los Gobiernos, las Instituciones, las Empresas proporcionan cada vez más datos, especialmente tras las directivas Europeas para fomentar el Open Data. Pero es que los propios individuos ahora proporcionan datos ingentes con su actividad, tanto de forma inconsciente como consciente.
Las compañías telefónicas y de Internet conocen toda nuestra actividad en todo momento. Desde la telefonía conocen todas nuestras llamadas, a quien, qué hemos hablado, cuanto tiempo, desde donde…
Los buscadores y otras páginas saben todo lo que hacemos, todo lo que buscamos, todo lo que miramos, desde donde lo hacemos.
Todo queda registrado, almacenado listo para su uso por miles de empresas; hemos de confiar en que el uso respeta la Ley sobre confidencialidad.
La mayoría de las grandes empresas permiten rastrear sus datos. Así twitter permite que nos descarguemos a nuestros ordenadores casi toda la información que se genera en su Red. El “casi” viene de que para que sea “toda”, debes pagar por los datos; pero en cualquier caso dan bastante. No así otras redes como Facebook. Tal vez esta racanería de Facebook sea una de las causas del mayor crecimiento de Twitter en los últimos tiempos.
El proceso de captura es laborioso y pasa por utilizar todas las últimas tecnologías. Como es habitual, es un mundo en rápida evolución que implica que hay que actualizar de forma constante las herramientas, infraestructuras, conocimientos, e incluso la forma de trabajo.

Primero capturamos los datos, luego la almacenamos y categorizamos.
Para capturar y almacenar todo esto, hace falta un CPD (Centro de proceso de datos) de tamaño medio. ¿Cuanto puede rastrearse y almacenarse en un centro típico? Pues digamos que la información que se rastrea y almacena durante un año puede rondar los 10 PBytes… o lo que es lo mismo, 1 MByte por cada persona ¿Cuánta información podemos entonces guardar sobre cada persona ?
Para aclararlo gráficamente, digamos que con esa cantidad de información, sobre cada persona del mundo podemos almacenar tanto como lo que cabe en la Primera Parte de El Quijote…
Pero vayamos al grano, o como nos gusta decir a los Físicos, al “núcleo” de la cuestión. Lo haremos con un ejemplo, lo más gráfico posible: Construyamos la Red de las llamadas por móvil de una compañía de telefonía.
Tomemos una persona y la representamos en un papel (o en una pantalla de ordenador…) por un circulo. Pongamos sobre el papel a todas las personas de la compañía: Miremos las llamadas de móvil de cada una. Fijémonos en “María” por ejemplo. María habrá llamado a 100 personas diferentes en el último año en la compañía. Pues ahora entre María y cada una de ellas, dibujamos una línea que las une, de un grosor proporcional al número de llamadas hechas a esa persona. Voy recorriendo todas las personas y obtendré una red llena de nodos (personas) y Links (llamadas). En general el dibujo será un galimatias, con millones de personas y miles de millones de links.
Esto no puede hacerse “a mano”, ni siquiera con un ordenador de andar por casa. Debemos procesarlo con ordenadores potentes y usar grandes bases de datos. Aquí es donde entra la Supercomputación y el Big Data.
Para poner algo de orden en semejante cúmulo de información hagamos una analogía, como nos gusta a los Físicos: basarnos en algo conocido para atacar lo desconocido (Tal vez procedemos así por falta de imaginación, de lo que los poetas están sobrados). Pensemos que nuestro sistema es como una Galaxia, donde las personas son estrellas, y las Links son las Fuerzas que existen entre ellas. Tenemos millones de fuerzas en juego y si dejamos a las estrellas que se vayan moviendo, que vayan evolucionando, como si del origen del Big Bang se tratase, se irán organizando desde la caótica situación inicial hacia las zonas donde cada una tenga mayor atracción; si la atracción es más fuerte, se pondrán más juntas, si no hay atracción se situarán en zonas alejadas, si no tiene relaciones con casi nadie, se irán a la periferia. Es decir simulamos la evolución de las personas como un proceso de formación de Galaxias, donde la fuerza de la Gravedad (la de Newton) viene sustiuida por la fuerza de atracción debida a las menciones, los retweets o la amistad en la Red Social a estudiar.
Tendremos finalmente un Mapa donde a simple vista veremos aglomerados (Comunidades) de personas afines que se han situado juntas pues tienen una relación más intensa entre sí que con el resto. Veremos miles de estos dominios o Comunidades, unas grandes, otras pequeñas, unas compactas y otras ligeras. Unas estarán en en el centro de la Galaxia, otras afuera.
Y veremos estrellas individuales de gran brillo pues son el centro de estas comunidades. Estrellas con gran relevancia pues se sitúan en posiciones de privilegio uniendo comunidades que si no fuera por ellas no tendrían comunicación entre si y estarían aisladas una de otra. Veremos estrellas vitales para mantener una Comunidad unida. Veremos estrellas cuya ausencia disgregaría el sistema, rompería su estructura. Incluso veremos estrellas que son los puntos semilla para que la información se propague de la forma más rápida y eficiente. Y muchas cosas más…
Algunas redes simples
Todo lo anterior tiene numerosas repercusiones prácticas.
Si quiero lanzar una campaña de propaganda personalizada puedo saber a que personas debo tocar para llegar rápidamente a toda la red, y a través que personas que se que son influyentes en sus opiniones.
Si quiero fidelizar a una comunidad, puedo saber a cuál de sus miembros debo hacer una oferta “que no podrá rechazar”.
Si quiero destruir una Comunidad de la competencia, puedo saber a quien debo atraer a mis filas, para que luego arrastre a los demás.
No hablemos ya de que incluso puedo saber quien está más cerca de cada uno, con sorpresas desagradables en los casos de fidelidades profesionales o personales, incluso amorosas.
La red de telefonía tiene problemas de confidencialidad, por eso mejor mostramos una red donde los nodos representan investigadores y la red se construye dibujando una Link cuando dos investigadores han firmado conjuntamente un artículo o colaboración científica. Para una mejor visualización, hemos dibujado el tamaño de cada nodo proporcional a su actividad científica total, y hemos coloreado de igual manera a cada Comunidad detectada matemáticamente como grupo Afín en el sentido descrito anteriormente.
Un ejemplo más atractivo podemos construirlo con la actividad en Twitter.
Supongamos que estoy interesado en el mercado de la cerveza y cómo se habla de ella, de las marcas, qué se opina, quien es quien en ese mundillo. Quiero saber como mejorar mi política de marketing, conocer las comunidades que crean opinión, los puntos fuertes de cada marca, etc…
Para ello fijemos unas cuantas palabras clave, hashtags y usuarios; buceamos un poco en Google, en twitter, en Internet en general para saber que palabras usa la gente en twitter para hablar de cerveza; finalmente elaboramos una lista del tipo:
doblemalta, porraestrella, exageradamentebuena, momentobrabante, cruzcampo, lazaragozana, cervezasambar, ambar, ponteambar, ambar especial, ambar1900, ambar premium, mahou, mahou_es, mahou san miguel, sanmiguel, mahousanmiguel, alhambra reserva, cervezaalhambra, alhambra_es, alhambra1925, estrelladamm, estrelladammes, estrella damm, volldamm, voll-damm, escoronita, cerveza dorada, cervezadorada, estrella galicia, estrellagalicia, amstel_es, moritz, moritzbarcelona, brabantecerveza, cerveza brabante, brabante cervezas, mahoudichos,…
Ahora, “levantamos” unas cuantas máquinas virtuales en “La Nube” que se dedicaran día y noche a rastrear y capturar todos los tweets que se emiten en el mundo tales que contengan alguna de las palabras anteriores. Vamos almacenando esos miles o millones de tweets para su análisis periódico.
El primer análisis es simple: cuantas veces aparece cada palabra clave, de quien se habla más, quien habla de quien, como evoluciona la actividad cada día, etc. Llamemos a todo esto “Estadísticas Clásicas”.
Una mirada a las Redes basadas en la actividad en Twitter
El segundo análisis, el motivo de este artículo, esta basado en la Física de los Sistemas Complejos, y lo primero que debemos hacer es definir la red colaborativa. Describamos la pieza básica: el tweet.
Para construir la red hay varias opciones. Consideremos la más simple. Los nodos de nuestra Red serán usuarios de twitter (los emisores). En un tweet tenemos un emisor, y podemos tener una mención a otro usuario de twitter. Entonces creamos una link entre el emisor y el receptor.
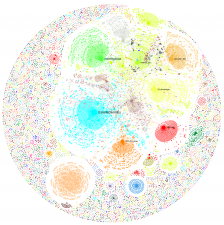
Con decenas de miles de tweets, con miles de usuarios y de menciones, obtenemos un rico mapa que es una fotografía viva de lo que la gente opina, de lo que la gente habla, incluso de lo que la gente está viviendo. En el caso del estudio de las cervezas, uno de los mapas resultantes tras una semana de seguimiento tiene la siguiente forma
Las posiciones corresponden con las afinidades, los colores con las comunidades naturales detectadas, el tamaño de cada punto con el número de menciones recibidas. Aparecen decenas de miles de personas, millones de relaciones entre ellas y vemos como se relacionan, com se posicionan, cual es su entorno, el papel que juega cada uno.
Se observa una region central con comunidades formadas por las principales marcas de cerveza. El color identifica las diferentes comunidades, y se nombra al miembro más relevante de cada una. La identificación de comunidades es completamente automatica, asi como la eleccion de los nombres a mostrar. El Mapa es muy reconocible, y muestra de forma rápida el Mapa de las Cervezas en twitter, que refleja las apetencias y usos de miles de usuarios en su actividad diaria.
La marca San Miguel, sin ser la de mayor numero de citas, ocupa el centro del Mapa dadas sus multiples relaciones con otras marcas. La mayor a simple vista es la de EstrellaDammEs.
La marca cervezasambar ocupa una posicion media, en la parte superior del Mapa.
No obstante aquí hay bastante ruido debido a usuarios y hashtags comunes, con nombres iguales, pero que no tienen relacion con la cerveza (por ejemplo la cantante Ambar…), rodeada por las marcas EstrellaGAlicia, Mahou y cervezadorada.
Las diferentes marcas tienen algunas comunidades satélite: por ejemplo en el caso de cervezasambar es la comunidad encabezada por sitioparapostre.
Tambien hay personas que juegan un papel destacado dentro de la comunidad, por su posición en twitter y por el papel que juega de conexión de la comunidad de cervezasambar con el resto de comunidades, como por ejemplo los usuarios polifoniksoud o RealZaragoza.
Un análisis calmado de este mapa da mucha más información sobre la estructura y la actividad en torno a las marcas de cerveza en España.
El Mapa es pues algo repleto de información.
Pero es evidente que hay un buen número de usuarios que hablan de temas bien diferente, son ruido. Por ejemplo hay una cerveza Ambar, pero también una cantante Ambar y por supuesto joyería de Ambar.
Actualmente, los análisis basados en Redes Complejas son los más eficientes para filtrar; veremos su potencia en este ejemplo a continuación.
En el Mapa, las comunidades periféricas y aisladas son grupos que hablan de temas que aparecen en nuestra lista, pero que no nos interesan.
Un opción para eliminar el ruido es quedarnos con lo que llamamos el “Cluster Gigante”: el núcleo más grande tales que todos los usuarios están conectados entre sí. Si bien hay otras muchas opciones en la Teoría de Redes, presentamos está por su sencillez. Obtenemos entonces un Mapa mucho más limpio.

Vemos ahora de modo más transparente el Mapa de las conversaciones de las cervezas en España.
En el mapa anterior tenemos una idea de la importancia de cada marca por el impacto visual de cada comunidad, coloreada. Podemos hacer eso más exacto agrupando cada comunidad en un único nodo, con un tamaño proporcional al número de menciones total dentro de la comunidad. Así vemos más rápidamente la importancia relativa de cada comunidad
Insistimos en que las posiciones, los colores son asignados automáticamente por algoritmos matemáticos. Incluso el nombre que figura corresponde al nodo mayor dentro de cada comunidad, que ¡Oh Maravilla! Corresponden con las distintas marcas de cerveza.
Podemos preguntarnos cosas más concretas, como por ejemplo cual es la subred, el entorno de una marca concreta. Para ello estudiamos el usuario cervezasambar, y sus vecinos y los vecinos de sus vecinos (por ejemplo). Es decir, el conjunto de personas que mencionan a cervezas ambar, y además lo que mencionan a todos los anteriores. Obtenemos el sigiente grafo

La estructura muestra nuestra cerveza de estudio en el centro de una potente comunidad, con mucho color azul, debido a que ha sido capaz de generar una comunidad propia, y ademas otras comunidades satélite, independientes pero fuertemente relacionadas. Este sistema estelar es el núcleo duro de nuestra marca, el lugar donde nuestra actividad de marketing será más eficiente y el campo donde la siembra de alguna promoción, información, o ideas, se propage rápidamente y por tanto sirva para expandirnos al resto de la Red de forma más segura y rápida.
En estos mapas, y en otros cientos que podemos dibujar, es posible ver el papel que juega cada comunidad, cuales son las comunidades afines, las más alejadas, las personas más importante en cada comunidad, las personas que conectan comunidades, la cohesión del sistema, la “distancia” entre personas (definida como el número de saltos en la Red para llegar de una a otra), y un largo etc.
De un estudio detallado de estos Mapas pueden extraerse numerosas directivas de actuación para ganar peso, posición, visibilidad, penetración en la Red, etc. etc.
De modo que estos mapas reflejan fielmente la realidad que nosotros conocemos y dan mucha información adicional. Del mismo modo, para un sistema que debamos estudiar y del que podemos desconocer casi todo, esta tecnología nos permite obtener una radiografía precisa y viva, con información fiable, veraz y de gran valor añadido.
Concluisiones y alguna recomendación
Hoy pocas son las grandes iniciativas empresariales, políticas, sociales que no se miran en las Redes para saber el lugar que ocupan y para tratar de posicionarse mejor, obtener beneficios económicos , de imagen o de votos.
Cada vez más la clásicas herramientas estadísticas, siendo siempre necesarias, se muestran cada vez más incompletas sin un análisis de Redes. En poco tiempo un estudio social será impensable sin un análisis de la Red que genera.
No hay duda pues que estas tecnologías de análisis social se harán un hueco cada vez mayor en las sociedades desarrolladas. Utilizarlas cuánto antes será una ventaja competitiva importante.
Pero hay que reconocer que hay ciertas sombras, una más técnicas otras más básicas. Entre las técnicas citaremos el problema de identificar si se está hablando mal o bien de algo: es decir, el problema del análisis semántico o de sentimiento de los textos capturados.
Dado los millones de frases analizadas, es imposible hacer el análisis y clasificación por humanos; es necesario pues un sistema automático (por ordenador).
Pues bien, a pesar de que muchos claman que disponen de un buen sistema de análisis de sentimiento, estamos muy lejos de que esto sea cierto. La fiabilidad no llega mucho más allá del 10% sobre el puro acierto al azar. El lenguaje coloquial humano es aún muy complejo para los ordenadores.
Entre los problemas más de fondo, se sitúa desde mi punto de vista, la relación entre Física y Sociología.
Los Físicos tienen un límite claro en su capacidad de análisis de estos fenómenos: los hombres no son granos de arena.
Los sociólogos tienen una cierta prevención para “sumergirse” en las nuevas tecnologías y herramientas de análisis.
Sin embargo la evolución social hace obligado el entendimiento. Los jóvenes vienen fuerte, y serán capaces de integrar en cerebros individuales lo que ahora vive en cerebros de físicos y sociólogos, y en ese momento dominarán el campo del moderno análisis sociológico.
Mientras tanto, desde este Blog, personas, y empresas estamos haciendo un esfuerzo para que aunque no podamos fundir los cerebros podamos fundir los conocimientos y ofrecer un producto competitivo e incluso algo adelantado a su tiempo.
Alfonso Tarancón Lafita.Catedrático de Física Teórica de la Universidad de Zaragoza.Director de Kampal Data Solutions SL. Especialista en Redes.Colaborador en alianza con CR Godoy & Asociados
Enlaces y articulos de interes:
















